Escaping the big data paradigm with compact transformers
Notes
Highlights
- The objective of this work is to propose a transformer-based architecture that does not require a huge amount of data during training (just as a reminder, VIT architecture is based on weights that have been pre-trained on over 100 million images !)
- The proposed architecture, “CCT” (Compact Convolutional Transformer) is shown to perform as well or better than CNNs for image classification on various scale datasets (ex: CIFAR10/100, Fashion-MNIST, MNIST and ImageNet)
- CCT brings a reduction of parameters of a factor of 30 during training (85 million to 3.7 million) compared to standard transformer architecture (ViT) with better performance
- CCT brings a reduction of parameters of a factor of 3 during training (10 million to 3.7 million) compared to CNNs (ResNet1001, MobileNetV2) for a given performance
- CCT is an end-to-end architecture that needs less than 30 minutes to be trained on small-sized datasets
Methods
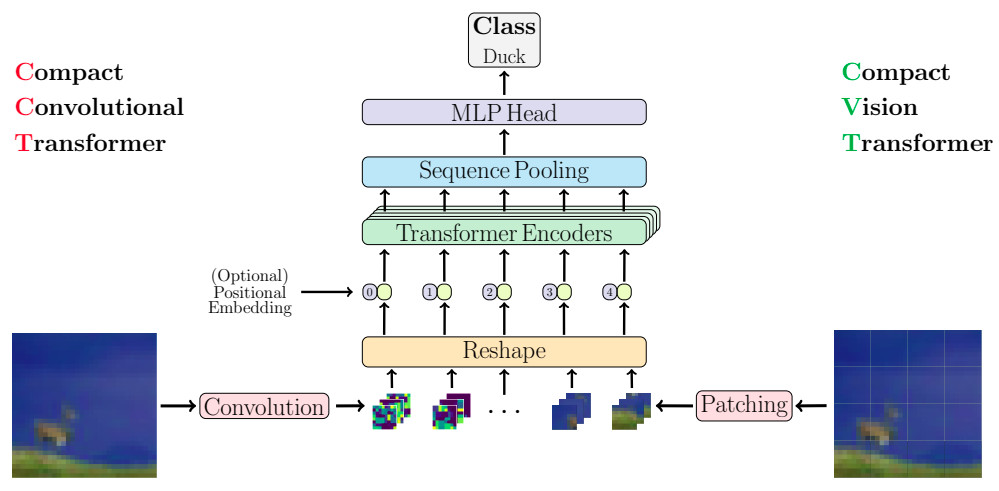
Architecture
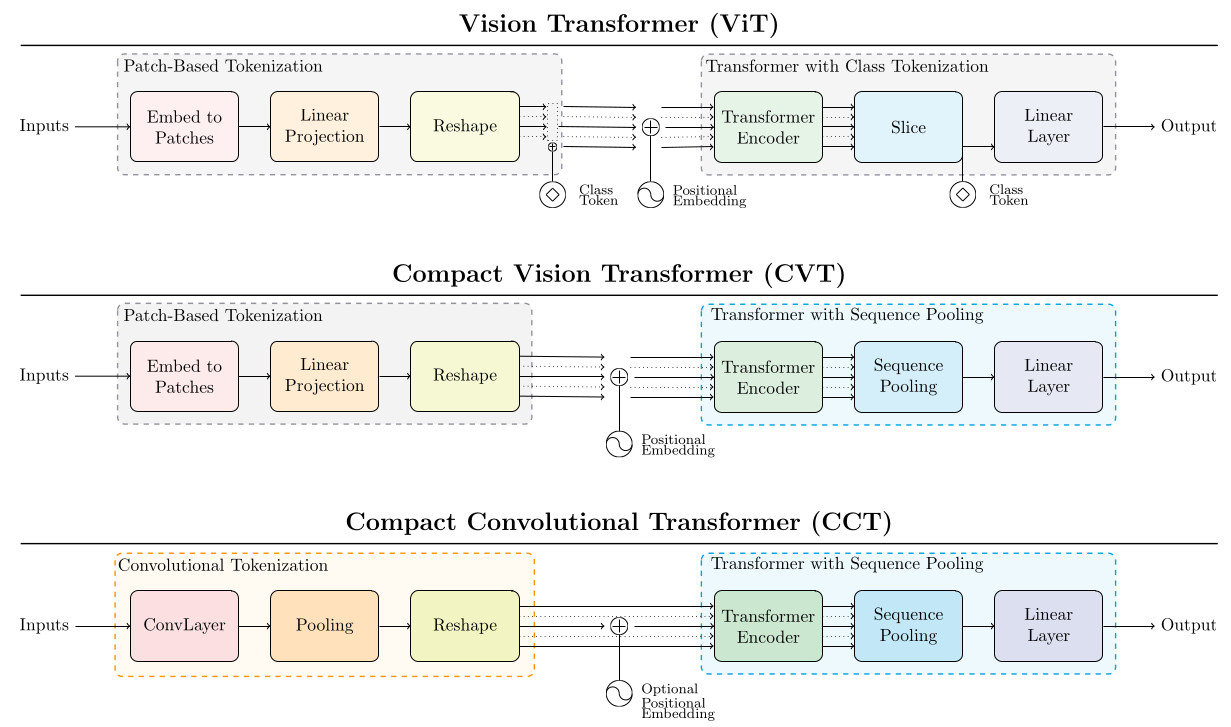
- Tokens are built from the input image thanks to a simple convolutional strategy. This step replaces the previous “tokenization” procedure (i.e., input image split into patches + linear projection).
- The class token strategy used in the ViT architecture is replaced by a sequence pooling procedure whose output is used as input for a simple MLP to perform classification.
- Several tests have also been done to reduce as much as possible the number of final parameters, in particular the number of blocks in the encoder, the kernel size of the input convolutional layers and the number of convolutional blocks. As an example, CCT-12/7x2 means CCT architecture with an encoder of 12 layers and 2 convolutional blocks with 7x7 convolutions to generate the input sequence of tokens.
- CCT reduces the influence of the positional embedding, which I think is appreciated :)
1st innovation: convolutional block
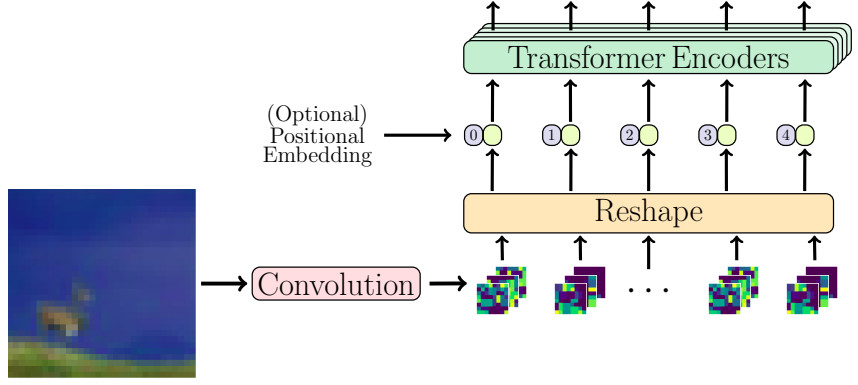
- Be careful, my feeling is that this figure is partially right (feature maps should be flatten to provide an information for each token)
- \(d\) filters (i.e., convolutions kernels) have to be learned to produce a sequence of \(d\)-dimensional kernels
- \[x_i = MaxPool\left( ReLU\left( Conv2d(x) \right) \right)\]
- \(x_i\) is a feature map whose individual value corresponds to the \(i\) component for each token.
- The number of tokens is directly linked to the image size and the size of the MaxPool operation.
- The output \(x_0\) of this tokenization procedure is of size \(\mathbb{R}^{b \times n \times d}\), where \(b\) is the mini-batch size, \(n\) is the number of tokens and \(d\) is the embedding dimension.
- This step allows the embedding of the image into a latent representation that should be more efficient for the transformer !
2nd innovation: sequence pooling
- Attention-based method which transforms (pools) the output sequence of tokens to a single \(d\)-dimensional vector \(z\).
- Let \(x_L \in \mathbb{R}^{b \times n \times d}\) be the output of the transformer encoder and \(g(\cdot) \in \mathbb{R}^{d \times 1}\) be a linear layer.
- An attention vector is first computed as follows: \(x'_{L}=softmax\left(g(x_L)^T\right) \in \mathbb{R}^{b \times 1 \times n}\)
- A weighted sum of the output of the transformer encoder is then performed: \(z = x'_{L} x_{L} \in \mathbb{R}^{b \times 1 \times d}\)
- The output of the sequence pooling can be seen as a final projection (through several attention blocks) of the input image into a latent space before the application of an MLP ! Some similarities with the encoding branch of CNN networks can be made :)
- The sequence pooling replaces the class token strategy of ViT-based architecture, which I find very interesting.
Comparison with the ViT architecture
Results
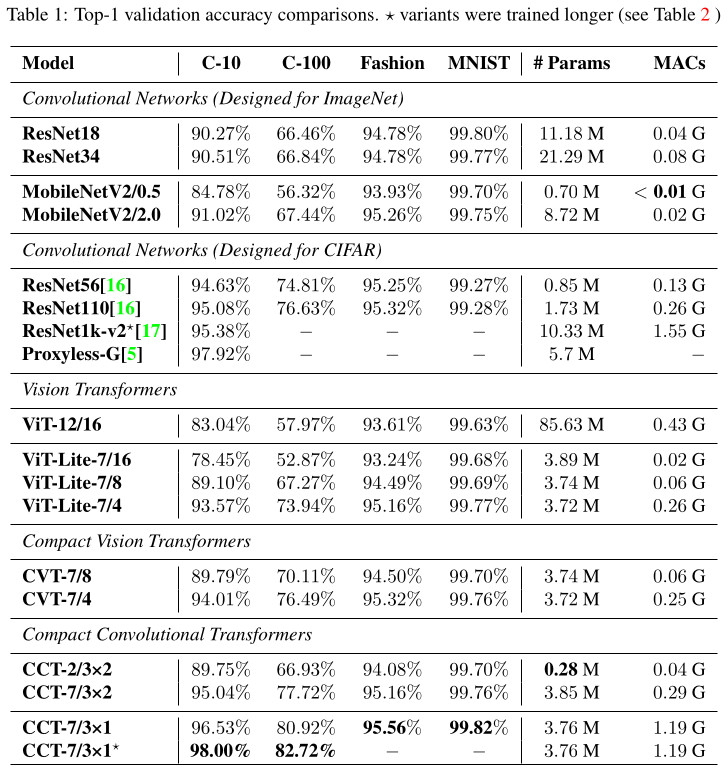
As seen in the table below, CCT performs slightly better than a very large ResNet, and definitely better that the ViT architecture, using significantly less parameters on small-sized datasets.
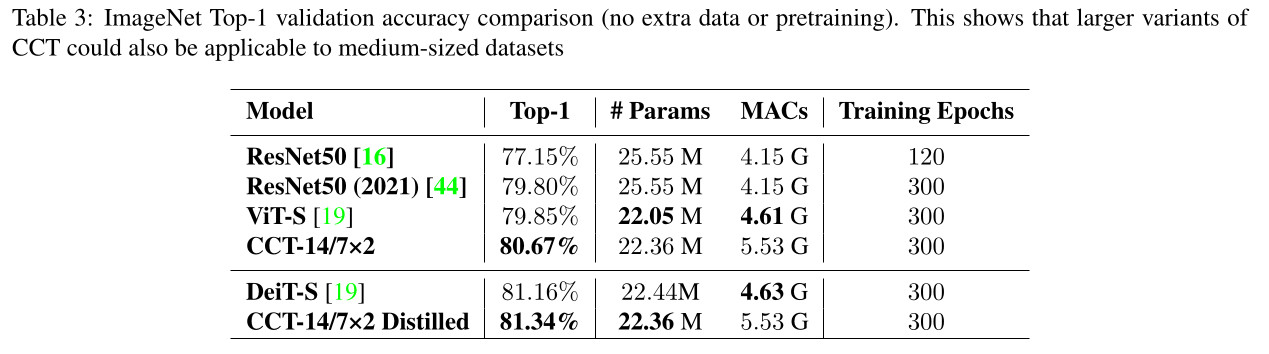
CCT also performs favourably on medium-sized datasets
Conclusions
Training end-to-end transformer networks from scratch on small-sized & medium-sized datasets with highly competitive results is possible !